
シロート統計学講座 其の8
其の7では連続変数を比較する統計解析の検定名について説明しました。今回は比率の比較と多変量解析の検定の選択方法について説明します。といっても、今回は検定の選択にはあまり迷わないので紹介程度です。

▼其の7がまだの方はこちら▼

Fisherの正確検定とカイ2乗検定
まずは今回紹介する統計解析の中で、唯一2つの検定が用意されている「③独立した2群間の比率を比較する」について説明します。

2つの検定はFisher(フィッシャー)の正確検定とカイ2乗検定ですね。この使い分けについては「EZRでやさしく学ぶ統計学」を参考にしてみましょう。
Fisherの正確検定とカイ2乗検定の選択については、前者は正確なP値を計算するものであるので統計解析ソフトで計算する場合には通常はFisherの正確検定を用いればよい。特にサンプル数(※1)が少ない場合やセルに含まれる対象の期待数が5未満の場合には(※2)カイ2乗検定は不適切である。逆に極端に大きなサンプルを用いる場合はFisherの正確検定では計算が困難になる場合があるのでカイ2乗検定を用いる。
引用:EZRでやさしく学ぶ統計学(P136-137)
※1 「サンプル数」は「サンプルサイズ」の意味で使用されていると考えられます。
※2 青字のところはひとまずスルーしてもらってよいです。この記事を書くにあたって初めて期待数の勉強をしましたが、結構簡単でしたので、いずれ紹介します。
▼2018.8.24追記【期待数について】▼

つまりは
●極端に大きなサンプルサイズを用いる場合:カイ2乗検定
を用いることになります。
ではサンプルサイズが「小さい」や「極端に大きな」とはどれくらいの数字のことなんでしょうか?これは下記サイトを参考にさせて頂きました。
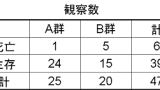
このサイトによると、次のようなことが書いてあります。
基本的にはサンプル数100未満ではカイ2乗検定は不適切となりやすいことを目安として知っておく必要がある。
※ こちらも「サンプル数」は「サンプルサイズ」の意味と思われます。
正確には期待数を計算する必要があると思いますが、サンプルサイズが100以下の場合はFisherの正確検定を選択すれば概ね間違いはない、と覚えておきましょう。
学会・論文ではカイ2乗検定の誤用が多くあるようですので、注意が必要ですね。
ちなみに「④対応のある2群間の比率を比較する」統計解析はMcNemar(マクネマー)検定だけですので、説明は省略します。
ロジスティック回帰・重回帰・Cox比例ハザード回帰
残りの検定については全て一択なので迷うことはなさそうです。よく論文などで見かけるのは「ロジスティック回帰」「重回帰」「Cox比例ハザード回帰」の多変量解析シリーズですね。

これ、検定名から覚えようとすると「何が何だか・・」となります。私もそうでした(汗)大事なのは検定名ではなくで、どんな統計解析なのかということなんですよね。
この3つの検定は全て多変量解析であることには変わりはありません。どんなデータを解析対象にしているかがキーとなります。
→ロジスティック回帰
→重回帰
→Cox比例ハザード回帰
というだけです。
検定名に惑わされないよう注意ですね。検定名は重要ではないですからね。
▼データの尺度が分からなくなったら▼

▼多変量解析や生存曲線の用語説明▼

ちなみに「⑩2群間の生存曲線を比較する」統計解析はLogrank(ログランク)検定といいます。
まとめ
これでSTEP2「統計解析の選択方法」まで修了です。今回は比較的あっさりといけたのではないでしょうか。次回以降、いよいよ無料統計ソフトEZRをダウンロードしてSTEP3「統計解析の実施方法」に移ります。
STEP1 統計解析の種類
STEP2 統計解析の選択方法
STEP3 統計解析の実施方法
STEP4 統計解析の結果解釈
EZRはマウスだけで簡単に操作できます。計算はEZRが一瞬でやってくれますので、私たちはどんな統計解析があって、どうやって選択して、どう結果を解釈するかを理解することが大事になりますよー。
▼其の9に続く▼



コメント